
- Use our web interface or API to quickly explore models.
- Pay a flat rate for your projects, research, or integrations.
- Enjoy privacy and robust security, with no logging of prompts or model outputs.
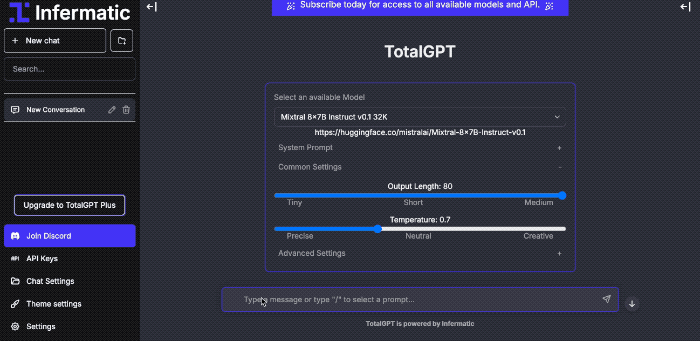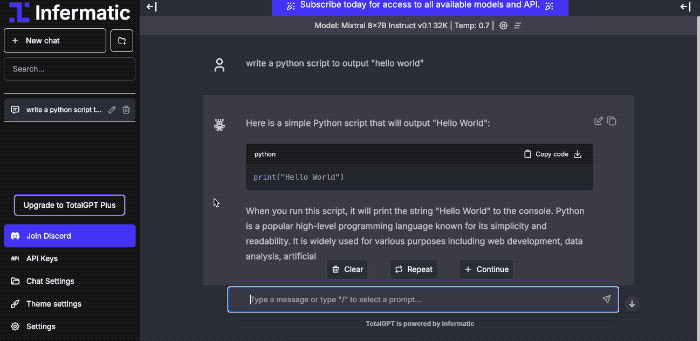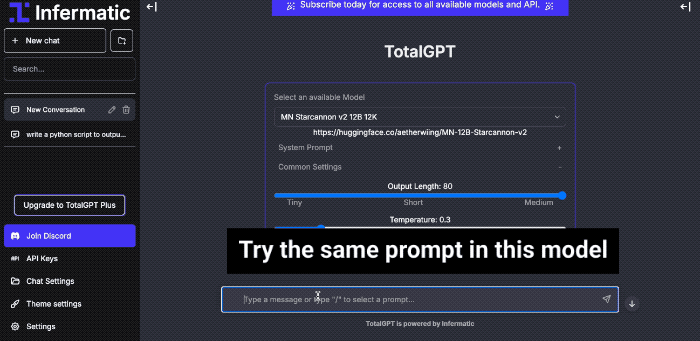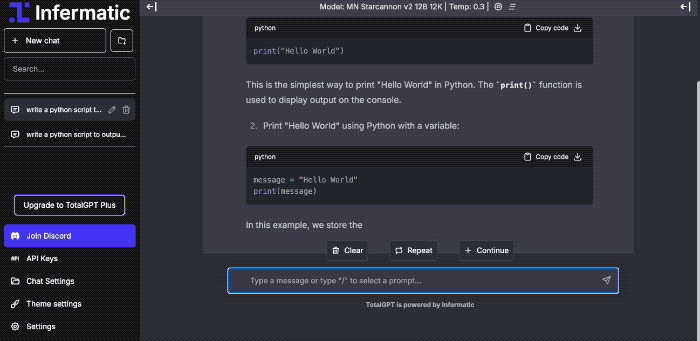
Web UI
API
Here are the top LLMs we’ve curated for you.
Updated frequently
Plus models
+ Standard, Essential, Free
Kokoro-82M
Standard models
+ Essential, Free
Prometheus 7b v2.0
Essential models
+ Free
multilingual-e5-base
Valkyrie 49B V1
Qwen3 Embedding 8B
Qwen3 VL 8B Instruct
Anubis 70B v1.1
Midnight Miqu 70B v1.5
Free models
Rocinante-12B-v1.1
How it Works
1. Discover
Get direct access to the best Large Language Models from Hugging Face’s LLM Leaderboard, all using the familiar user interface you know.
2. Choose your model
Test, tinker, and pinpoint the model that resonates with your content needs or business strategies.
3. Scale
As your needs evolve, Infermatic adapts. From niche projects to enterprise-level initiatives, the Infermatic platform scales with you. You’ll always have the right LLM tools at hand and at the scale you need.
Speed to market is critical, so don’t let setup slow you down.
We take the Ops out of MLOps.
You get instant access to leading LLMs with zero infrastructure management.
Infrastructure is off your critical path.
Say goodbye to:
Infrastructure management
Forget the complexities of setting up and overseeing servers, especially for large-scale, parallel processing.
Latency & cold starts
Eliminate optimization woes and cold start delays. Enjoy consistent, rapid model responses.
Version control headaches
No more headaches over managing multiple model versions, or ensuring the correct one is active.
Integration complexity
Effortlessly integrate ML models into your projects, regardless of differing tech stacks. Let seamless integration be your new normal.
Scalability concerns
Grow your projects without fear of scalability limitations. As your user numbers grow, our back end gracefully handles the surge.
Cost management issues
Keep cost under control and forget about escalating server and cloud expenses. Devote your budget to your project, not infrastructure.
UP TO DATE
We frequently update the models we support. Details on all our models.
COMMUNITY
Participate in the discussion, ask questions, and help us select models. Join our Discord server.
Why Infermatic?
Simple
Infermatic’s clean design is user-friendly and familiar, so you can focus on your work without the clutter of irrelevant features.
Privacy
Unlike some services, we don’t log your prompts or results. Your inputs remain yours, and not part of the LLM information base.
Unrestricted Results
Experiment without guardrails on a secure platform. Iterate your product to its full potential.
Scalable
Infermatic scales with your business so you have the necessary resources when you need them at each stage of your growth.
Absolutely Secure
We safeguard your data. Our systems are up to date and incorporate strong encryption end-to-end.
No Coding Necessary
Infermatic is intuitively designed for any user who can write a good prompt. Navigate with ease, focus on crafting your narratives or strategies, and let us manage the back end complexities.
LLMs Trained for Your Use Case
Engage with the same user interface you love from GPT, but without the limitation of only one LLM. Explore what’s possible, including LLMs trained specifically for your use case.
Automatic Model Versioning
Seamlessly manage and transition between model versions, ensuring that you always deploy the most updated and efficient version without the hassle of manual configuration and updating.
Real-Time Monitoring
Stay ahead with instant insights. Monitor model performance and health in real time, allowing for swift interventions and optimal operations.
Deploy state-of-the-art models with just a few lines of code.
Infermatic supports multiple deep learning frameworks, including:
LibreChat
Novelcrafter
Wyvern
SillyTavern
Frequently Asked Questions from Geek to Geek
- What is prompt engineering, and why is it critical in working with LLMs?
- How can I design effective prompts for LLMs?
- What are some standard techniques used in prompt engineering?
- How does prompt length impact the output of an LLM?
- How do LLMs understand and generate human-like text?
- What is the difference between Llama, Mixtral, and Qwen?
- What are some examples of advanced use cases of prompt engineering with LLMs?
- How do I choose the best LLM model for my project?
- What are large language models, and how do they differ from traditional NLP models?
- Can LLMs write code well?